

What does Siri and machine translation have in common?
They both produce strange, sometimes ridiculous language that leaves us shaking our heads with confusion.

Robot Dog
However, as much help as these tools have been to us, there is one thing they have never been able to get right: our name, IVANNOVATION. Our name is a portmanteau; that means two words put together. The first part sounds like the name Ivan. And second sounds like the word innovation. Put them together and you get IVANNOVATION.
How Siri and Google transcribed the word IVANNOVATION
Siri and Google’s dictation tool have had quite a time understanding our name. Here are a few of the things they thought we were saying:
Devon ovation
If I have a shin
Aunt is on vacation
Avon ovation
Ivana patient
Devon evasion
Avant avation
Ivanovic
Yvonne evasion
Evo Novation
Yvonne of Asian
Ivanov Asian
If on a vacation
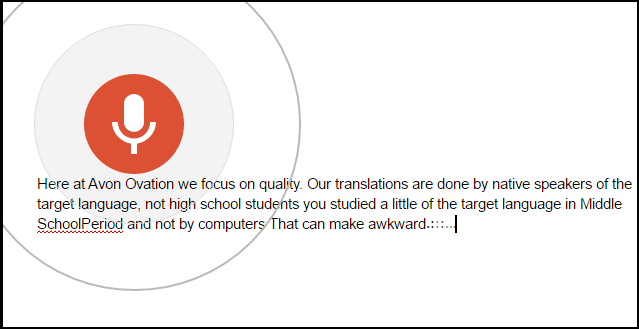
Google dictation on a Google Docs document
Transcriptions and funny Siri responses
Siri, in particular, makes things even more interesting since she, or it, has to dictate what we say and then respond to it. Here are some of the exchanges we have had with Siri:
Us: “Where is IVANNOVATION?”
Siri: “Where is Yvonne of Asian” . . . “I didn’t find any matching restaurants.”
Us: “I’m working at IVANNOVATION.”
Siri: “I’m working out of AutoNation.” . . . “Ok, I’ll remind you.”
Us: “I’m doing this project for IVANNOVATION.”
Siri: ”I don’t know what that means. If you like, I can search the web for ‘I’m doing this project for of on a vacation.’”
Us: “What does IVANNOVATION do?”
Siri: “Here’s what I found on the web for ‘What does it on invasion do?’”

What this Means for Machine Translation
Clearly, Siri and Google dictation are getting some of what we say but not quite getting it perfect. That’s because computers get all out of whack when they have to deal with the way humans think and speak. Computers love things to be formulaic like algebra. They want all spelling to be exactly the way it should be like this:
jQuery code
But when we confront them with the unpredictable, nuanced, and contradictory world of human expression full of inference and creativity, they lose their way. How can they presume to understand a vague reference to a popular movie that just came out and takes, for example, “May the force be with you” to mean “good luck”?
This is the boundary fence at the edges of the computer’s ability to understand the natural language of humans, which computer programmers and scientists keep moving slowly back but can never really eliminate.

Fence
That’s why those of us at IVANNOVATION, a translation company, are not getting nervous at advances of the computer’s abilities in natural language processing and machine translation. Machine translation, like that provided by Google Translate, is useful yet inaccurate and unnatural.
Google translation and other machine translation engines share similar natural language processing challenges as Siri and Google’s dictation tool, and they make similar kinds of mistakes.
Two Kinds of Machine Translation
These mistakes come from the way the language gets processed in a machine translation engine. When humans translate, they have some understanding of the underlying meaning behind the words in the text. Humans do not just process words. We process ideas, feelings, facts, and opinions. Computers don’t do that. They just process words.

Some robot
They do this in a few different ways. There are two broad categories of the types of machine translation engines: rules-based engines and statistical-based engines.
Rules-based
Rules-based systems are basically programmed by taking bilingual dictionary entries coupled with a detailed system of grammar conversion rules to tell the computer how to change the text. So, for example, to translate “I am going at 6:30” to Spanish, the computer would translate each word. Then it would reorder the words according to Spanish grammar.
There are several problems with this system. One problem is that some languages have grammatical features and tenses that other languages don’t have. It’s easy to translate from the more “detailed” language to the simpler language. However, when translating from the simple language to the more complex language, how can the computer choose between two of the possible grammatical forms?
Another problem with this system is that it is fairly good at translating similar languages, but the more the languages differ, the crazier the translation becomes.
Finally, the rules-based machine translation system requires a detailed system of grammatical conversion rules for the language pair. If that system of rules doesn’t exist, the computer can’t translate.

Robodog
Statistical-based
Statistical-based machine translation systems are created by importing a massive corpus of translated texts to the computer. When you enter a text to translate, the computer will then look for how a particular word or phrase in that text was translated in the corpus you gave it earlier. It can also look at the context of a word, so the word “type” in the phrase “type of animal” can translate differently from the same word in the phrase “type something on the computer.”
However, statistical-based systems also have problems. If a language pair has only a few documents that have been translated, the statistical-based machine translation engine will not be able to translate well. The quality of the translation depends directly on the amount and quality of the corpus of texts that programmers give it. For example, Google Translate improved dramatically in 2005 when Google trained it with 200 billion words of translated text from the United Nations. The smaller the corpus of translated text, the lower the quality of the translation. That’s bad news for you if you are trying to translate Telegu to Wolof.
Further, the quality of the translation also depends on the type of corpus. If the corpus is a collection of translations from proceedings at the United Nations, your translations of a TV show for American teens may be incomprehensible. The expressions used by delegates at the UN and those used by teens at the school cafeteria differ widely. Imagine Justin Bieber saying thoughtfully, “I resolutely concur with the resolution put forward by Ludacris.”
Uses for Machine Translation
Machine translation is not a bad thing, however. Individuals browsing web pages that are not pre-translated will always find Google Translate to be a helpful resource. They can find out the main idea of what they are looking at even if the wording is awkward.

Chrome offering to translate Yahoo Japan
Sometimes, a company has a large amount of text that is not that important, but needs to be read by people in another language. If the company lacks the budget to get a good translation of it, they will run it through machine translation. It fills an immediate need and doesn’t break the bank.
Another use which has been growing recently is machine translation with human post-editing. The translation, completed by a computer, is then passed to a human translator who cleans up the text and makes it more readable, natural, and accurate. This method saves some money and takes less time than a complete human translation. Depending on the corpus used to train the system, it can be good for some types of less important and more straightforward documents. But, it is not recommended for more nuanced and creative content.
Should I Use Machine Translation?
There are many legitimate uses for machine translation. But, if the text that needs translation is important, and if customers and potentials will be reading it, the text must be translated.
Or at least post-edited by a human translator.
Just like Siri and Google’s dictation tools often completely miss the intent of the user, so machine translation can frequently make mistakes that a person would never make. Only humans can really understand the intent of the original writer and convey that intent in another language in a natural and engaging way.
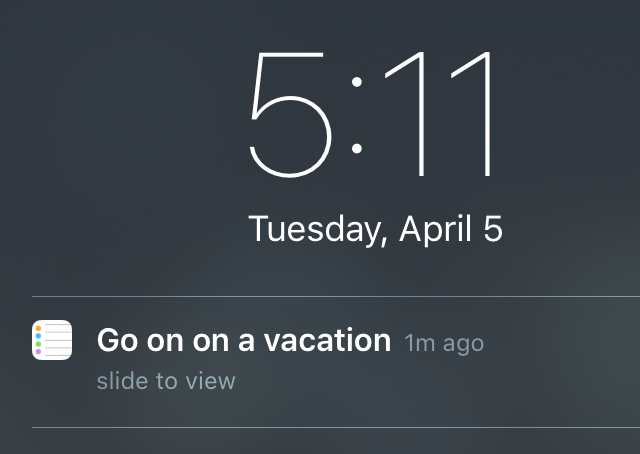
Funny Siri responses: Siri thinks “Go to IVANNOVATION” means “Go on on a vacation.”
photo credit: Dorron via photopin (license)
photo credit: See Spot Run — Dog vs. Robot via photopin (license)
Darren Jansen, Business development and content manager for IVANNOVATION has a lifetime love for tech and languages. At IVANNOVATION he helps software developers get professional localization for their apps, software, and websites. On his time away from the office, he can be found hiking the Carolina wilderness or reading Chinese literature.
